已有账号,去登录
竞赛圈 > 第一名方案分享
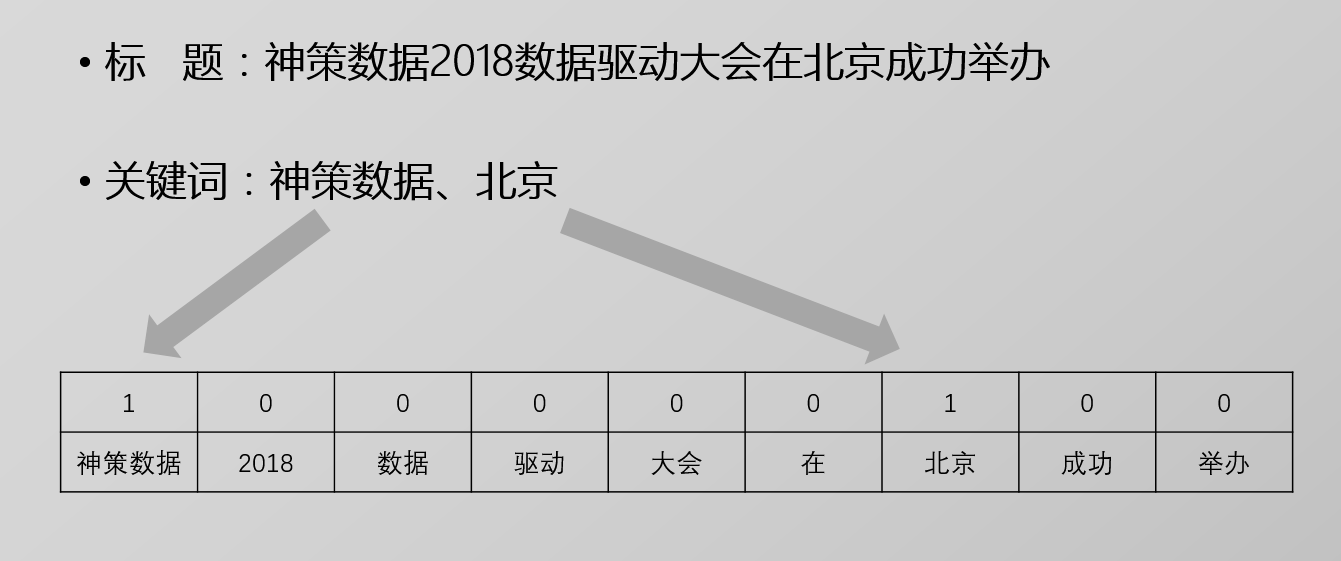
基本框架是KEA算法,也就是将关键词提取转化为二分类问题。
举个栗子:
核心部分的特征提取代码如下:
# 产生特征的函数
def gen_feature(id, text):
# 读取分词结果
a,b=cut(text)
# 清洗分词结果
title_words = clean(a)
context_words = clean(b)
# 读取词性标注结果
postag = dict(cuter5ed.find_one({'id': id})['postag'])
c = cuter6ed.find_one({'id': id}, )['pos']
# 计数
tf_title = Counter(title_words)
tf_context = Counter(context_words)
# 计算总词数
freq = tf_title + tf_context
total = sum(freq.values()) # 总词数
# 计算tfidf并排序
tfidf = {}
for k in freq:
tfidf[k] = freq[k] * idf_freq.get(k, median_idf) / total
tfidf_tuple = sorted(tfidf, key=tfidf.__getitem__, reverse=True)
# 筛选候选词
candidates = set([j for j in tfidf_tuple[:num_of_word_extract]] + title_words)
# 开始提取特征,此处用dict不用pandas.DataFrame是出于效率考虑
rrl = {}
for w in candidates:
s = dict()
pos_ = postag.get(w, 'REST')
newpos = pos_[0]
s['tfidf'] = tfidf[w] # tfidf系数
s['tf_title'] = tf_title[w] # 标题中词频
s['tf_context'] = tf_context[w] # 内容中词频
s['rank'] = tfidf_tuple.index(w) # tfidf系数排名
s['pos'] = pos_ # jieba分词给出的词性
s['new_pos'] = newpos if newpos in ['n', 'v', 'x', 'R'] else 'H' # 对jieba分词结果进行处理
s['hanlp_pos'] = search_pos(w, c) # hanlp的词性标注
s['title_position'] = text['title'].find(w) # 首次出现位置
s['title_position_r'] = len(text['title']) - text['title'].rfind(w) # 最后一次出现位置(倒着数)
s['title_position_rr'] = text['title'].rfind(w) # 最后一次出现位置(正着数)
s['position'] = text['context'].find(w) # 首次出现位置
s['position_r'] = len(text['context']) - text['context'].rfind(w) # 最后一次出现位置(倒着数)
s['position_rr'] = text['context'].rfind(w) # 最后一次出现位置(正着数)
s['length'] = len(w) # 词汇长度
s['idf'] = idf_freq.get(w, median_idf) # idf逆序数
# s['local_idf']=local_idf.get(w,10.2063)
s['train_freq'] = ck.get(w, 1) - 1 # Relu一下,避免过拟合。
s['in_title'] = 1 if w in title_words else 0 # 是否在title中
rrl[w] = s
r = pd.DataFrame.from_dict(rrl, orient='index')
r['tf_title_gm'] = r['tf_title'].mean() # 组均值
r['idf_gm'] = r['idf'].mean() # 组均值
r['doclen'] = len(text.context) # 文本总长度
r['tf_title_rk'] = r['tf_title'].rank() # tf排序
r['idf_rk'] = r['idf'].rank() # idf排序
r['id'] = id # 文档编号
r['wid'] = r.index.map(lambda j: j + id) # 词与文档编号拼接,作为unique的index
r.reset_index(inplace=True, drop=False)
r.set_index('wid', inplace=True)
r.rename({'index': 'word'}, axis=1, inplace=True)
return r
在按照上述步骤,对候选词逐个处理之后,再进行统一处理如下(出于速度考虑):
# 处理特征
def handle_features(this_set):
# 加载word2vec模型,进行词汇向量化嵌入
model_w2v = Word2Vec.load('../pickles/model_w2v')
wv_name = ['w2vec_{}'.format(k) for k in range(20)]
words = [k for k in set(this_set.word) if k in model_w2v]
w2v_dict = dict(zip(words, model_w2v.wv[words]))
w2v = pd.DataFrame.from_dict(w2v_dict, 'index')
w2v.columns = wv_name
this_set = this_set.join(w2v, on='word').fillna(0)
del model_w2v, w2v
gc.collect()
# 加载doc2vec模型,进行文档向量化嵌入
dv_name = ['d2vec_{}'.format(k) for k in range(20)]
model_d2v = Doc2Vec.load('../pickles/model_d2v')
ids = set(this_set.id)
d2v_dict = dict(zip(ids, [model_d2v.docvecs[j] for j in ids]))
dv = pd.DataFrame.from_dict(d2v_dict, 'index')
dv.columns = dv_name
this_set = this_set.join(dv, on='id')
del model_d2v, dv
gc.collect()
# 计算余弦距离
this_set['cos_distance'] = cal_cosd(this_set)
# 处理成pandas.Categorical格式,便于分类器识别
this_set.pos = pd.Categorical(this_set.pos)
this_set.new_pos = pd.Categorical(this_set.new_pos)
this_set.hanlp_pos = pd.Categorical(this_set.hanlp_pos)
# 是否在自定义词典中
this_set['is_book'] = this_set.word.str.upper().apply(lambda k: k in bid)
this_set['is_txkw'] = this_set.word.str.upper().apply((lambda k: k in a4))
this_set['is_txkw2'] = this_set.word.str.upper().apply(lambda k: k in a3)
# 词中是否包含数字、英文字母
letter = re.compile('[A-Za-z]')
digit = re.compile('[0-9]')
this_set['have_letter'] = this_set.word.map(lambda w: bool(letter.search(w)))
this_set['have_digit'] = this_set.word.map(lambda w: bool(digit.search(w)))
return this_set
矩阵化计算余弦相似度的函数如下:
# 用矩阵计算的方法,一次性计算一组词的cosine距离
def cosgroup(g):
x = g.values
i = x.sum(1) != 0
z = np.zeros(i.shape)
x = x[i, :]
y = x.T
u = np.dot(x, y)
u1 = np.sqrt(np.sum(np.multiply(x, x), 1))
u1 = np.dot(u1.reshape([-1, 1]), np.ones([1, x.shape[0]]))
u2 = u1.T
r = u / np.multiply(u1, u2)
z[i] = r.mean(1)
return z
# 计算cos距离
def cal_cosd(s):
t = s[['w2vec_{}'.format(k) for k in range(20)]].groupby(s.id)
res = []
for tp, g in t:
res.append(cosgroup(g))
return np.hstack(res)
BTW:MacBook的OS X系统好难用!
 关注微信公众号
关注微信公众号
